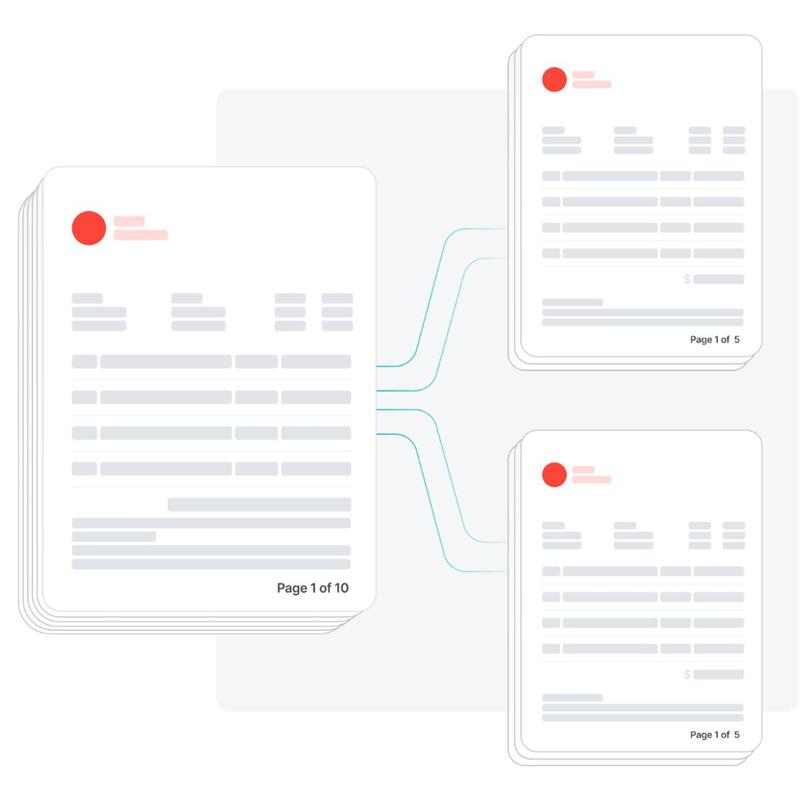
In the realm of Intelligent Document Processing (IDP), handling multi-document files has long posed a critical challenge. Business operations often involve scanning and uploading physical paper bundles—like invoices, receipts, or contracts—into a single PDF file. But what happens when each page (or a few pages) in that PDF belongs to a completely different document? That’s where Document Splitting comes into play. It is no longer just a convenience. It’s a necessity.
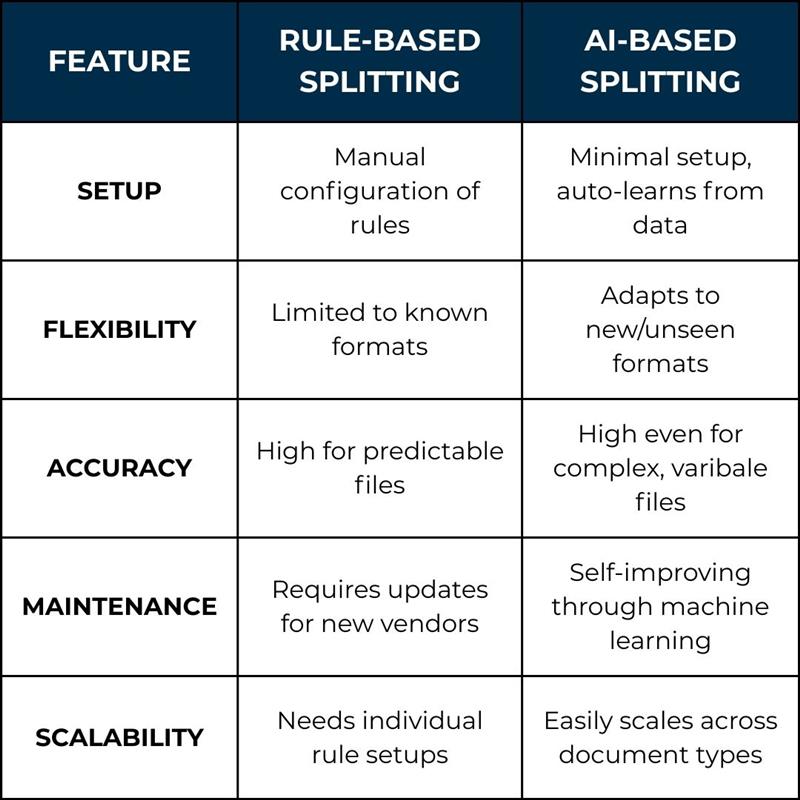
DocAcquire initially addressed this problem using rule-based splitting—a flexible and powerful solution. But as document structures grew more complex and business workflows more dynamic, we realized rules alone weren’t enough. Enter AI-Based Document Splitting: our latest evolution in document processing that intelligently understands and splits documents without manual rules.
Let’s explore the journey from rule-based to AI-based document separation and how DocAcquire is pushing the frontier of automation.
Document splitting is the process of separating a single file—usually a scanned PDF or digital document—into multiple individual documents based on specific criteria. This is essential when multiple documents are bundled together into one file but needs to be separated for independent processing or storage.
This becomes particularly critical in high-volume document environments like finance, legal, or healthcare, where batches of documents are scanned together for efficiency. Without an automated way to split them, manual extraction becomes a tedious, error-prone, and time-consuming task.
For example, consider scanning a batch of 50 invoices from different vendors into one consolidated PDF. Each invoice might vary in length, ranging from one to three pages. Without document splitting, you would have to manually scroll through the file, identify where each invoice starts and ends, and then extract them one by one. This not only slows down the workflow but also increases the risk of missing or misfiling documents.
By applying document splitting, the system can automatically analyze the file, detect logical breaks between documents—such as recurring headers, footers, vendor names, or invoice numbers—and divide the PDF into individual invoices. Each resulting file can then be independently processed for data extraction, routed for approval, or archived systematically. This significantly enhances efficiency, accuracy, and scalability in document processing workflows.
Rule-based document splitting is the traditional and foundational approach to dividing multi-document files. It operates using predefined logic to identify document boundaries, making it highly effective when the structure and format of incoming documents are consistent and predictable.
In DocAcquire, users could configure rule-based splitting based on:
1.Fixed Number of Pages
This method assumes each document within a file has the same page count. It is ideal for scenarios where every document—such as invoices, forms, or shipping labels—occupies a uniform number of pages. For instance, if a supplier sends a 10-page PDF containing ten one-page invoices, the system can be configured to automatically split the file at every single page interval.
2. Text-Based Markers
Many documents include recurring textual patterns or headers that signal the start of a new document. Examples include terms like “Invoice #,” “Statement Date,” or “PAGE: 1.” DocAcquire can scan for these textual markers and use them as reliable indicators for when a new document begins. This approach adds more flexibility than page-based splitting, particularly for documents of variable length that still follow a consistent internal labeling pattern.
3. Field-Based Splitting
Leveraging AI-extracted fields such as document_id, invoice_number, or purchase_order_number, DocAcquire can intelligently determine where one document ends and another begins. When the system detects a change in the value of these key fields across pages, it interprets this shift as a boundary, prompting a split. This method is particularly powerful for semi-structured documents where field values consistently distinguish one document from the next.
These rule-based configurations cover a wide range of practical use cases and offer a high degree of control. However, they require upfront manual setup and some domain-specific knowledge to define the right logic. More importantly, rule-based methods tend to struggle when document layouts vary, when textual markers are inconsistent or missing, or when scanned content has OCR errors or noise. In such cases, more dynamic and intelligent approaches—like document splitting with AI—become essential for achieving accuracy and scalability.
While rule-based document splitting performs reliably in structured environments, its effectiveness begins to decline as real-world document variability increases. In practice, many organizations face challenges that render static rules insufficient or too fragile to maintain at scale. Some of the most common limitations include:
1. Variability in Document Structure
Vendors and partners frequently change the layout or design of their documents—sometimes without notice. A new logo, an additional coversheet, or even a change in page order can break existing splitting rules. What worked for last month’s batch may fail silently today, leading to incorrect splits or missed documents.
2. Missing or Inconsistent Fields
Key fields like document_id, invoice_number, or purchase_order—often used to determine boundaries—may not appear consistently on every page. For instance, the first page may contain the invoice number, but the following pages might lack any identifier. Rule-based systems struggle to infer continuity across such pages, resulting in either fragmentation or missed splits.
3. High Maintenance Overhead
As business relationships grow and new document formats are introduced, rule sets must be manually updated, tested, and validated for each variation. This creates an ongoing maintenance burden for IT teams or business users and increases the likelihood of human error or outdated configurations.
These limitations underscore the need for a more intelligent and flexible approach to document splitting—one that can adapt to diverse formats, recognize subtle structural cues, and improve over time without constant manual intervention.
This growing complexity has driven many organizations to explore document splitting with AI, which leverages machine learning, content understanding, and layout analysis to detect logical document boundaries with greater accuracy and significantly less manual effort. With AI-based document separation, businesses can handle varied and unstructured document formats more reliably, paving the way for smarter automation and more scalable document processing workflows.
To address the limitations of rule-based methods and meet the demands of increasingly diverse document streams, DocAcquire has introduced AI-powered document splitting—a transformative leap toward intelligent automation. This intelligent approach eliminates the need for rigid rules by using machine learning models trained to understand document structure, layout, and content contextually.
At its core, document splitting with AI in DocAcquire mimics how a human might approach the task: by reading and interpreting the content of a document, recognizing logical boundaries, and identifying contextual signals that indicate the start of a new record. Unlike traditional rule-based logic, which depends on explicit patterns or fixed configurations, the AI models are capable of handling:
1. Structural Layout Recognition
Using computer vision and natural language processing (NLP), the AI understands layout elements such as headers, tables, line breaks, section titles, and whitespace patterns. This enables AI-based document separation to accurately detect splits, even when formatting varies significantly across vendors or document types.
2. Content-Aware Understanding
Rather than depending on specific keywords or fields, the AI evaluates text in its full context—identifying recurring elements such as invoice numbers, customer IDs, and addresses. This AI-based document splitting approach ensures that documents are correctly separated, even when fields appear in unpredictable formats or locations.
3. Cross-Page Continuity Detection
AI can recognize when content flows logically from one page to the next (e.g., a multi-page contract or invoice) and when a new document begins—something that rule-based systems often misinterpret. This drastically reduces false splits and ensures that related pages stay grouped together.
4. Adaptability and Learning
DocAcquire’s AI-based document separation system can be fine-tuned over time, learning from feedback and adapting to new layouts or document types. This makes it a robust, scalable solution for enterprises processing high volumes of diverse documents from multiple sources.
By integrating automatic document splitting driven by AI, DocAcquire empowers organizations to automate the most complex and variable aspects of document ingestion. The result is faster, more accurate processing, less manual configuration, and a scalable solution that grows smarter over time.
Thanks to our new AI-powered document splitting, DocAcquire makes it easier than ever to manage your documents. Here’s how it helps:
✅ Faster Processing with Less Setup
Traditional systems often require you to manually define rules or templates for every document type—this can be time-consuming and complicated. With document splitting with AI in DocAcquire, there’s no need for that. The system automatically understands where one document ends and another begins by analyzing patterns, headers, or content structure. This automatic document splitting enables you to begin processing immediately, accelerating your workflow with minimal setup.
✅ Fewer Mistakes
Manual document handling and rule-based systems are prone to errors—especially when documents don’t follow the expected format. Our AI-powered document splitting approach doesn’t depend on fixed rules, so it can adapt to variations in layout, language, or structure. This flexibility helps avoid mistakes like splitting documents in the wrong place or missing important sections, leading to more reliable and accurate results across your intelligent document processing workflows.
✅ Easier to Grow
As your business expands, you’ll encounter new vendors, customers, and document formats. Traditional systems require ongoing updates to splitting rules, which can become a bottleneck. With AI-based document separation, DocAcquire continuously learns and adapts—no need for constant reconfiguration. This makes it easy to scale and onboard new document types without disrupting your operations.
✅ Better Data Extraction
When documents are correctly split from the beginning, the systems that follow—like those used for extracting invoice numbers, dates, or customer names—can perform much more accurately. Clean, well-separated documents reduce confusion and errors, helping you get the right data faster. This improves the end-to-end performance of your intelligent document processing pipeline.
Finance & Accounting
Use Case: Splitting multi-invoice PDFs into individual files and routing them for automated data capture and approvals.
In finance departments, it’s common to receive bulk PDFs containing multiple invoices—either scanned or digitally generated. Manually separating these invoices is time-consuming and error prone. With intelligent document processing, businesses can implement automatic document splitting to detect invoice headers, supplier logos, and consistent formatting cues. Document splitting with AI enables the system to accurately segment each invoice into standalone documents. Once split, these documents can be routed to specific workflows for data extraction (e.g., invoice number, vendor, amount) and forwarded to appropriate approvers, accelerating accounts payable processes and reducing manual intervention.
Healthcare
Use Case: Dividing large medical reports into patient-specific records using AI-detected boundaries.
Hospitals and diagnostic labs often generate consolidated PDFs containing results for multiple patients, especially in high-throughput environments. Splitting these into patient-specific documents is crucial for privacy, accuracy, and record integrity. With AI-based document separation, systems can identify patient details like names, birthdates, or IDs to segment each report. This form of document splitting with AI ensures that individual records are cleanly separated, ready to be uploaded into Electronic Health Record (EHR) systems or securely shared with patients, streamlining compliance and patient care.
Logistics
Use Case: Separating delivery dockets and packing slips from scanned bundles for streamlined shipment processing.
In logistics, documents like delivery notes, packing slips, and bills of lading are frequently scanned together. Relying on manual sorting slows down operations and risks misfiling. Automatic document splitting powered by intelligent document processing uses layout recognition and keyword spotting to identify and isolate each document type. By applying document splitting with AI, businesses can ensure accurate classification and seamless integration into shipment tracking, inventory updates, and fulfillment workflows.
Legal & Compliance
Use Case: Automating splitting of contracts and legal agreements for better record-keeping and review workflows.
Legal departments often deal with bulk contract documents, including annexures, amendments, and multiple agreements in one scan. Splitting these documents allows each contract or agreement to be handled separately—making it easier to index, review, sign, and archive. With AI-based document separation, DocAcquire can detect common legal structures such as section titles, clause numbers, or standard phrases (e.g., “This Agreement,” “IN WITNESS WHEREOF”) to divide content logically. Document splitting with AI also enhances compliance by ensuring timely audits and simplifying document retrieval.
With the launch of AI-Based Document Splitting, DocAcquire is taking Intelligent Document Processing to the next level. This powerful feature automatically separates large or bundled documents—like invoices, medical reports, contracts, and shipping forms—into individual files without any manual effort. By using AI to detect page boundaries and content patterns, it ensures greater accuracy and saves valuable time. Businesses can now streamline their workflows, reduce errors, and boost productivity, all while handling documents more efficiently than ever before.
Smarter Splitting. Seamless Automation. Only with DocAcquire.
Want to see it in action?
Check out our video to witness how effortlessly AI-based Document Splitting works in DocAcquire — automatically identifying and separating documents with precision, no manual setup required!
Ready to transform your document workflows? Get started with DocAcquire today to see AI-Based Document Splitting in action!
Back to blog
At DocAcquire, we’re committed to not only streamlining document processing with intelligent automation but also ensuring that our platform is easy to navigate, user-friendly, and efficient for...
Read article
In today’s fast-paced business environment, time is money — especially when it comes to processing documents. Whether you’re dealing with vendor invoices, contracts, utility bills,...
Read article
In the realm of Intelligent Document Processing (IDP), handling multi-document files has long posed a critical challenge. Business operations often involve scanning and uploading physical paper...
Read article
In today’s digital world, documents are everywhere — whether it's invoices from suppliers, contracts with clients, purchase orders, insurance claims, onboarding forms, or any other business...
Read article
In today’s fast-paced business environment, organizations are increasingly relying on automation to handle massive volumes of documents. However, manual data entry and document processing are...
Read article
What is PDF? PDF (Portable Document Format) is a file format that is used to present and exchange documents reliably, independent of software, hardware, or operating system. PDF was invented by...
Read article